Recently, I have learned about the move semantics of C++ 11 from Bo Qian’s YouTuBe Channel. As an “old boy” that is curious to all kinds of new techniques, I definitely would give myself a try.
Define a Class
First of all, I create the following C++ class (which is similar to the one used in Bo Qian’s Video), i.e.,, Note that, all “#include” are omitted.
class exampleA {
int *x;
int size;
public:
// default constructor
exampleA(): x(NULL), size(0) {
std::cout << "Default constructor is called" << std::endl;
}
// constructor from a std::vector
exampleA(const std::vector<int>& vec){
size = vec.size();
x = new int[size];
for (int i = 0;i < size;++ i) x[i] = vec[i];
std::cout << "Create exampleA object from vector" << std::endl;
}
// copy constructor
exampleA(const exampleA& other)
{
std::cout << "Copy constructor is called" << std::endl;
size = other.size;
if (size > 0) {
x = new int[size];
for (int i = 0;i < size;++ i) x[i] = other.x[i];
}else
{
x = NULL;
}
}
// move constructor
exampleA(exampleA&& other)
{
std::cout << "Move constructor is called" << std::endl;
size = other.size;
x = other.x;
other.size = 0;
other.x = NULL;
}
// deconstructor
~exampleA() {
if (x != NULL) delete [] x;
x = NULL;
size = 0;
std::cout << "Deconstructor is called" << std::endl;
}
// friend function: overloading operator <<
friend std::ostream& operator<<(std::ostream& os, const exampleA& a);
};
// definition of (or implementation of) overloading operator <<
std::ostream& operator<<(std::ostream& os, const exampleA& a){
for (int i = 0;i < a.size;++ i) os << a.x[i] << " ";
return os;
}
Define two Functions
Then, I defined a function that returns an exampleA object and another function that uses an object from the class exampleA as a parameter as follows.
// function to create an exampleA object
exampleA createObject(){
exampleA a(std::vector<int>(10, 1));
return a;
}
// function uses an exampleA object as a parameter
void passByValue(exampleA a) {
std::cout << a;
}
“Moment to Witness the Miracle”
Next, I though the moment to witness the miracle (Chinese: 见证奇迹的时刻) was coming. I created the following use cases to verify my understanding.
int main()
{
exampleA a(std::vector<int>(10, 1));
passByValue(a);
std::cout << "======================================\n\n";
passByValue(createObject());
return 0;
}
Before “witnessing the miracle”, let us first do some simple analysis to figure out what the “miracle” is. According to the above use cases, we first create an exampleA object – i.e., a – from an std::vector. Then we passed a to the function passbyValue by value, since a is a lvalue, we would expect the copy constructor to be called. And then, we passed a rvalue createObject()
to the function passbyValue, we would expect the move constructor to be called.
However, the following presents the output from running the above example (by using g++ -std=c++11 example.cpp -o example && ./example)
Create exampleA object from vector
Copy constructor is called
1 1 1 1 1 1 1 1 1 1
Deconstructor is called
======================================
Create exampleA object from vector
1 1 1 1 1 1 1 1 1 1
Deconstructor is called
Deconstructor is called
Unfortunately, we failed to witness the most important part of the miracle, i.e., the move semantics.
Dig Out of The Chief Culprit
After Google, Google, … and Google again, I eventually found “the chief culprit”. It is the copy elision feature of the compiler. Now, it is really the moment to witness the miracle. The following gives the final outputs after disabling the copy elision (add a flag -fno-elide-constructors, that is to run g++ -fno-elide-constructors -std=c++11 example.cpp -o example && ./example).
Create exampleA object from vector
Copy constructor is called
1 1 1 1 1 1 1 1 1 1
Deconstructor is called
======================================
Create exampleA object from vector
Move constructor is called
Deconstructor is called
Move constructor is called
1 1 1 1 1 1 1 1 1 1
Deconstructor is called
Deconstructor is called
Deconstructor is called
From the above outputs, you can see that the move constructor was called twice. First call was during the returning from the function createObject, and the other one is during passing value to the function passByValue.
In this post, we investigate how to efficiently delete certain elements from a Python list. More specifically, you want to delete certain elements, whose indices are given.
Solution A: Move to A New List
def removeA(myList, removalIndices):
if not isinstance(removalIndices, set):
removalIndices = set(removalIndices)
return [v for i, v in enumerate(myList) if not (i in removalIndices)]
This solution moves elements that do not need remove to a new list. Clearly, it would not be quite efficient when the number of removals is much less than the length of the original list. Besides, if the indices of the removals are not stored in a set but a list, the conversion from list to set would further drop the efficiency.
Solution B: Remove From The Last
def removeB(myList, removalIndices):
for removalIndex in removalIndices[::-1]:
del myList[removalIndex]
return myList
This solution removes the elements from the last (the one with the largest index) to the first (the one with the smallest index). This solution assumes that the indices of removals are sorted in an ascending order. Note that, removing from the first one is not a good idea, since each removal will change the indices of the remaining removals. In other words, for removals other than the first one, you have to recalculate the index before removing.
Solution C: Shift Removals Together Then Remove
def removeC(myList, removalIndices):
nextRemovalIndex = removalIndices[0]
indexOfRemovalIndices = 1
numOfRemovals = len(removalIndices)
lenOfList = len(myList)
currentIndex = nextRemovalIndex + 1
while currentIndex < lenOfList:
nextIndex = removalIndices[indexOfRemovalIndices] if indexOfRemovalIndices < numOfRemovals else lenOfList
while currentIndex < nextIndex:
myList[nextRemovalIndex] = myList[currentIndex]
nextRemovalIndex += 1
currentIndex += 1
indexOfRemovalIndices += 1
currentIndex += 1
# pay attention
myList[-numOfRemovals:] = []
return myList
This solution first shifts all the removals to the end of the list, and then removes them. Note that, this solution also assumes the indices of removals are sorted in an ascending order. Compare to Solution B, it guarantees that every element that needs move just moves once.
Which One Will Be More Efficient?
- Dense Cases (
myListhas $10^6$ elements, removing $80\%$)-
Random locations
Solution A (with
listrepresenting removals, i.e.,removalIndicesis alist): 159.12msSolution A (with
setrepresenting removals, i.e.,removalIndicesis aset): 134.69msSolution B: 1.13ms
Solution C: 132.39ms
Remarks: during the measurements, I found that the
setcreate from different status (e.g., sorted or unsorted) of alistwill have different efficiency. I will investigate this in details in future. -
From the beginning
Solution A (with
listrepresenting removals, i.e.,removalIndicesis alist): 187.58msSolution A (with
setrepresenting removals, i.e.,removalIndicesis aset): 133.30sSolution B: 7403.70ms
Solution C: 221.80ms
-
From the ending
Solution A (with
listrepresenting removals, i.e.,removalIndicesis alist): 133.34msSolution A (with
setrepresenting removals, i.e.,removalIndicesis aset): 142.03sSolution B: 0.74ms
Solution C: 121.12ms
-
- Sparse Cases (
myListhas $10^6$ elements, removing $0.2\%$)-
Random locations
Solution A (with
listrepresenting removals, i.e.,removalIndicesis alist): 134.81msSolution A (with
setrepresenting removals, i.e.,removalIndicesis aset): 149.77msSolution B: 216.96ms
Solution C: 159.68ms
-
From the beginning
Solution A (with
listrepresenting removals, i.e.,removalIndicesis alist): 150.39msSolution A (with
setrepresenting removals, i.e.,removalIndicesis aset): 153.45msSolution B: 2098.12ms
Solution C: 182.74ms
-
From the ending
Solution A (with
listrepresenting removals, i.e.,removalIndicesis alist): 131.15msSolution A (with
setrepresenting removals, i.e.,removalIndicesis aset): 134.47sSolution B: 204.69ms
Solution C: 163.19ms
-
TODO
- analyze the above results
- efficiency of set creating from different status of a list
- while loop versus splicing
TiKz provides a very efficient way for us to “program” our figures. However, sometimes you might only want to share your figures but not the source codes of your figures with other for some reasons (e.g., the source code uses a large amount of TiKzlibrary, other people might not have these libraries in the machine or you just want to make your codes private). In this post, we present a way to generate eps figure from TikZ source code (Of course, you can also generate a PDF and let others include that PDF).
LaTeX Code
\documentclass{article}
\usepackage{tikz}
%% put tikzlibrary below if necessary
% set up externalization
\usetikzlibrary{external}
\tikzset{external/system call={latex \tikzexternalcheckshellescape -halt-on-error
-interaction=batchmode -jobname "\image" "\texsource";
dvips -o "\image".ps "\image".dvi;
ps2eps "\image.ps"}}
\tikzexternalize
\begin{document}
%% put your tikz code below or input your tikz code via \input
\end{document}
Usage
latex -shell-escape LATEX_FILE_NAME
Please make sure you are using latex engine, other engines
will not work. Besides, please make sure all required tools
are installed.
SSH is a commonly used remote-access solution. The popularity of various cloud based solutions brings “some challenges” in the usage of SSH to remotely access the servers in the could. Because, you might have a lot of VMs in the cloud, and they might have different IP address/URL, username and passport. This would become a nightmare if you only know the “elementary” SSH commands.
In this post, we will introduce you some “advanced” SSH configurations. For ease of presentation, we assume you have two VMs in the cloud, their identities are as follows:
- A
- domain name: hostA.com
- username: userA
- password: passwdA
- B
- domain name: hostB.com
- username: userB
- password: passwdB
Note that, unless explicitly stated, we assume all the configurations are on your local computer.
Generate SSH key
Please refer to Play with Github
Upload SSH Public Key to VM A/B
Copy the content of your public key and add it to the end of the file ~/.ssh/authorized_keys on VM A (note that if the file does not exists, you need create one.).
Similarly, upload SSH public key to VM B.
Configure Local SSH
Add the following content at the end of your ssh configuration file, i.e., ~/.ssh/config
Host A
HostName hostA.com
User userA
IdentityFile path/to/ssh-private-key
Host B
HostName hostB.com
User userB
IdentityFile path/to/ssh-private-key
Now, you can remotely access VM A simply by ssh A.
More Advanced Tricks To Be Appeared
- Showing GUI
- Showing GUI from a VM behind NAT
- Creating SSH tunnels to “bypass” access gateway
This post details the steps for building and using a “LaTeX IDE” with Sublime Tex 2/3 and LaTeXTools. For ease of presentation, we will call sublime text 3 as ST3 for short, similarly we will use ST2 stands for sublime text 2.
Download and Installation
- Download ST3 for your operating system.
- Install
- Window/Mac: GUI install, just doubly check the file you downloaded, and follow the instructions.
- Ubuntu: here assume you have downloaded the deb installation file, open a terminal and type in the following command
sudo dpkg -i path/to/sublime_text_3_deb_file
Configuration
-
Manually (Semi-manually) install Package Control (Note that, Package Control is the only package that you need install manually. It seems that the latest version of ST3, you can also install this package like other packages.)
ctrl + `(command + `if you use Mac) to open the console, and copy the corresponding codes into the console and then pressenter.
-
Install package LatexTools
ctrl + shift + p(command + shift + pif you use Mac) to open the command Platte for Package Control- Find and click “Package Control: Install Package”
- Enter “LaTexTools” to search and click on the “LaTexTools” to install
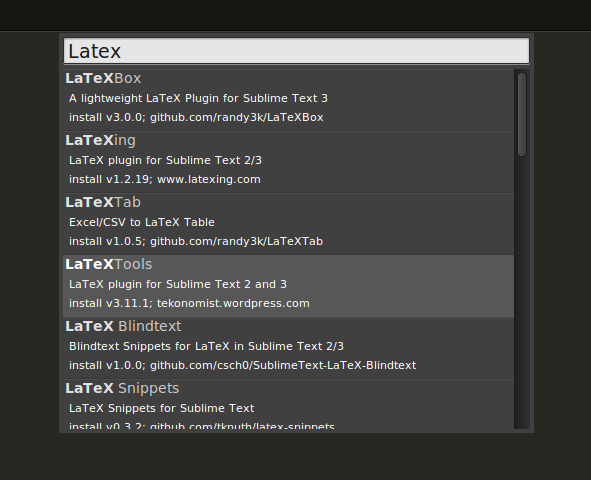
-
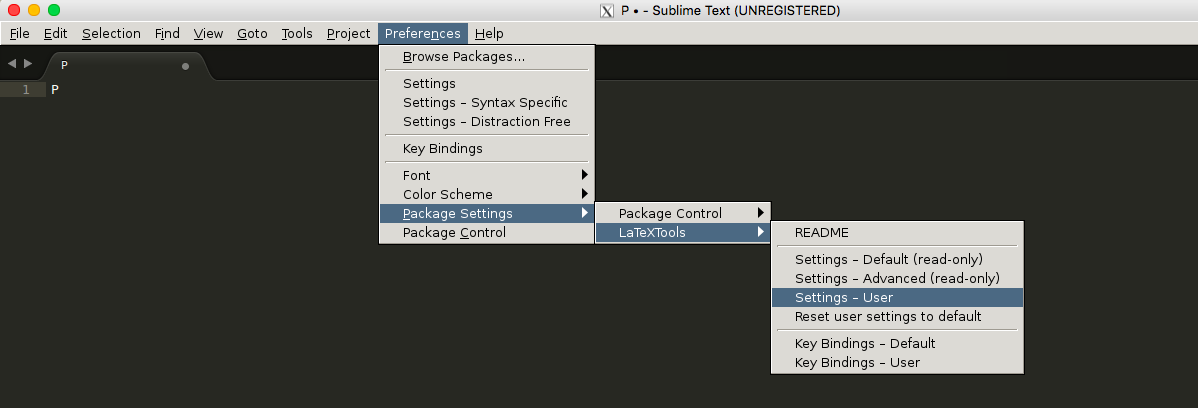
Configuration (optional only if you want to use the customized build script)
- Open the configuration for LaTeXTools and “OK” for all pop-up windows.
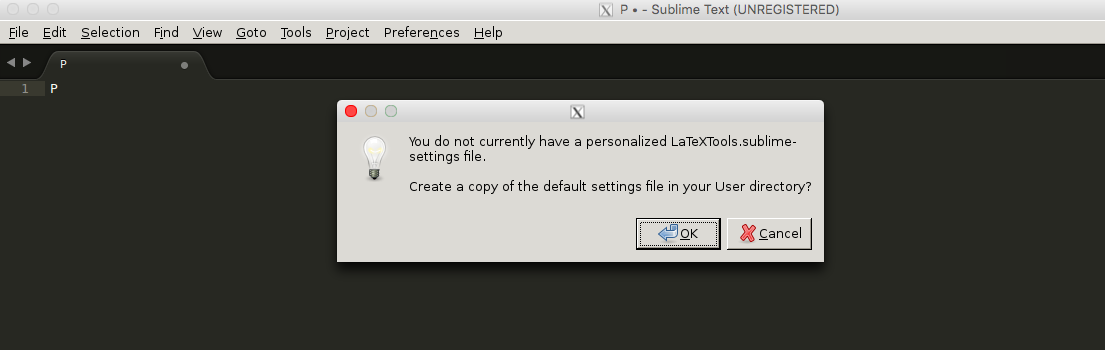
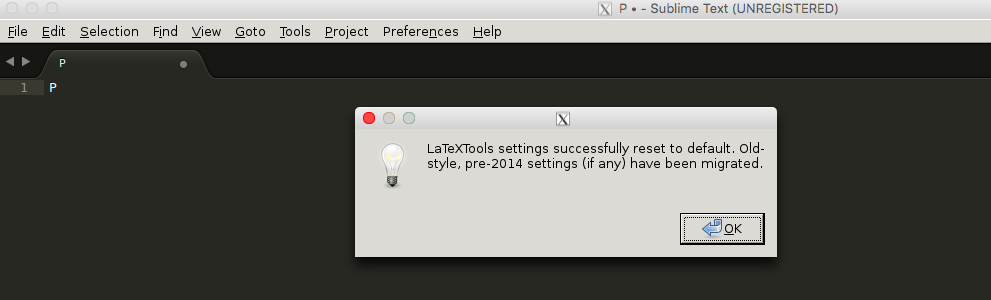
- Replace the content with this one
- Open the configuration for LaTeXTools and “OK” for all pop-up windows.
Remark: To use the above customized configuration, you need the following tools (note that, for the latest version of Ubuntu, all tools are built-in in the OS.)
- Ghostscript
- Windows
- Mac:
brew install ghostscript
- PDF Viewer
- Windows: SumatraPDF
- Mac: Skim
Usage
Please refer to LateXTools for Cross Reference in Multi-file LaTeX Projects
In this post, we will introduce a method to help you easily do cross reference in a multi-file latex project (i.e., a latex project where latex source files are distributed into multiple files). For example, the file structure of a multi-file latex project might look like:
path/to/your-latex-project/
main.tex
introduction.tex
related-work.tex
my-work.tex
evaluation.tex
conclusion.tex
reference.bib
figures/
In the above project, you might cross cite for example an algorithm which you define in the file my-work.tex in the file evaluation.tex. Without the assistance of some useful tools, you might have to check the file my-work.tex to make sure which label you have defined for that algorithm. And in some tools, they might automatically remind you all the labels you have defined in the current file, which means they cannot help you in the cross-file cross reference.
In this post, we will describe you an easy method to help you do the cross-file cross reference by using the LaTeXTools plug-in of Sublime Text. Note that in this post, we will focus on the configuration for cross-file cross reference. If you have no idea on how to install the LaTex Tools or even Sublime Text, please ask Google or some other search engine.
Create a Sublime Text Project
Create a sublime text project for your multi-file latex project. If you have no idea on how to create a project in sublime text 2/3, please refer to understanding-projects-in-sublime-text-saving-switching-etc.
Configure Your Project
After you create your project, you will see a auto-created file (named as your-project-name.sublime-project) in your root path of your multi-file latex project. Open the file, and the put the following configurations into the file.
"settings" : {
"TEXroot": "main.tex",
"tex_file_exts": [".tex"]
}
The above configuration assumes, the root latex file of your project is main.tex (if your project use another tex file, please change it correspondingly.). If you really want to make a full understanding of the above configurations, please refer to Project-Specific Settings of the Latex Tools.
The following is for those who are not so familiar with JSON, i.e., the format for the project setting file. Usually, before you do manual changes on the project setting file, its content looks as follows:
{
"folders":
[
{
"path": "."
}
]
}
After you add the configurations, your setting file would look as follows (please pay attention to the comma after the ], it cannot be omitted):
{
"folders":
[
{
"path": "."
}
],
"settings" : {
"TEXroot": "main.tex",
"tex_file_exts": [".tex"]
}
}
Please pay attention to the comma added after the close square bracket (i.e., ]).
Notice
If you have any suggestions or questions regarding this post, please lease your message in the comment session or send e-mail to mr.gonglong@outlook.com directly.
SD-EONVP is a network virtualization platform that provides efficient interfaces for customers to create and manage their virtual networks whose underlying infrastructure is the flexible-grid elastic optical networks. It extends the open-source project OpenVirteX (OVX) in the following three aspects: 1) it supports quantitative bandwidth allocation ( of course only for elastic optical networks) by providing spectral resource virtualization to OVX; 2) it provides high efficient built-in virtual network embedding algorithms; 3) it provides convenient interfaces based on web GUI for customers to create and manage their virtual network.
System Overview
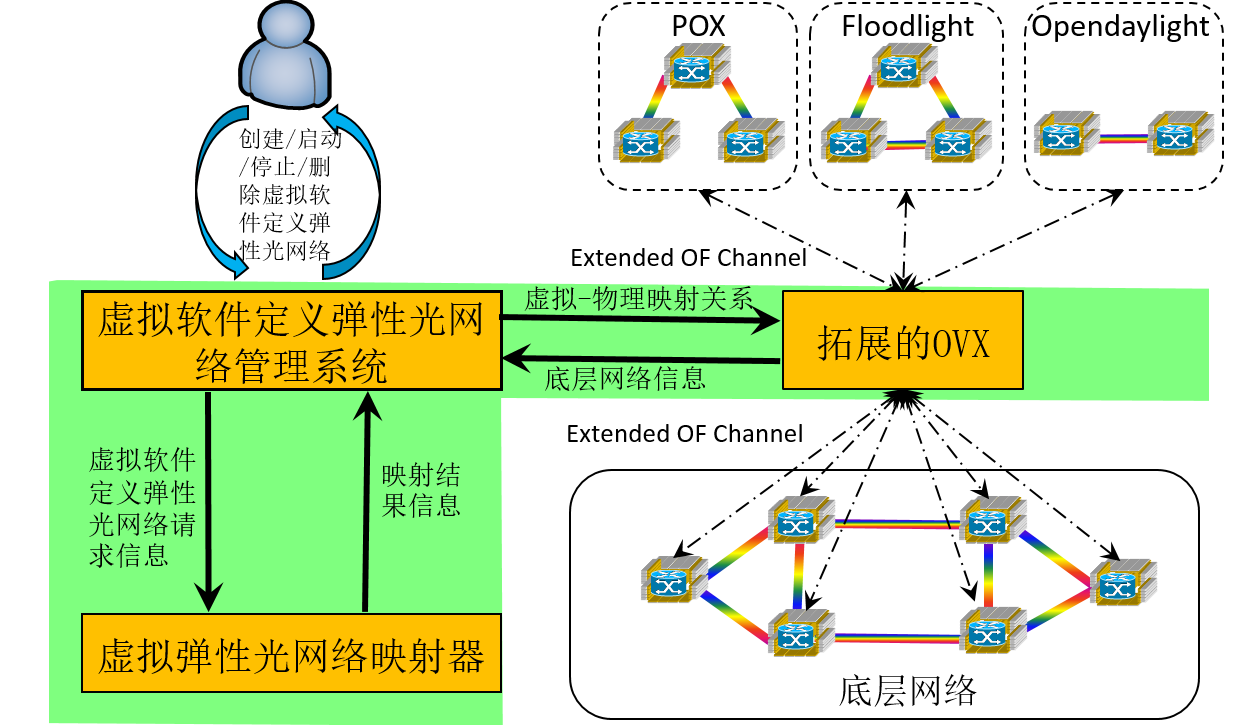
The above figure shows the overview of our network virtualization system. From it, we can see there are three major modules in our system.
-
Virtual Software-Defined Virtual Network Management Module
A Web GUI for users (or customers) to create and manage their virtual networks continently.
More details you can refer to the video demo in the following part and my master thesis
-
Network Hypervisor (Extended OpenVirteX, E-OVX for short)
A openflow-based network hyper-visor supporting for network virtualization
It is based on OpenVirteX, we did protocol extension on it (i.e., making it support quantitative bandwidth allocation for elastic optical network based on the concept of spectral virtualization)
More details you can refer to the official web of OpenVirteX
-
Virtual Network Embedder
The module is to conduct virtual network embedding, which is one of the major challenges in network virtualization. In the platform, we have built in some efficient virtual network embedding algorithms.
Motivations to separating it from Network Hyper-visor
Easily upgrade
Easily debug
Major Principle
-
Topology Virtualization
Based upon LLDP, creating an “illusion” (for the controller of the virtual network) that the topology of the virtual network is the same as what the customer wanted
-
Address Virtualization and Spectral Virtualization
based on OpenFlow, rewriting the addresses and spectral information at the ingress and egress switches to make the controller of the virtual network believe that it “owns” the whole network
More details, you can refer to OpenVirteX official web or my master thesis
A Video Demo
The following video shows how a user applies our network virtualization platform to create and manage their virtual networks.
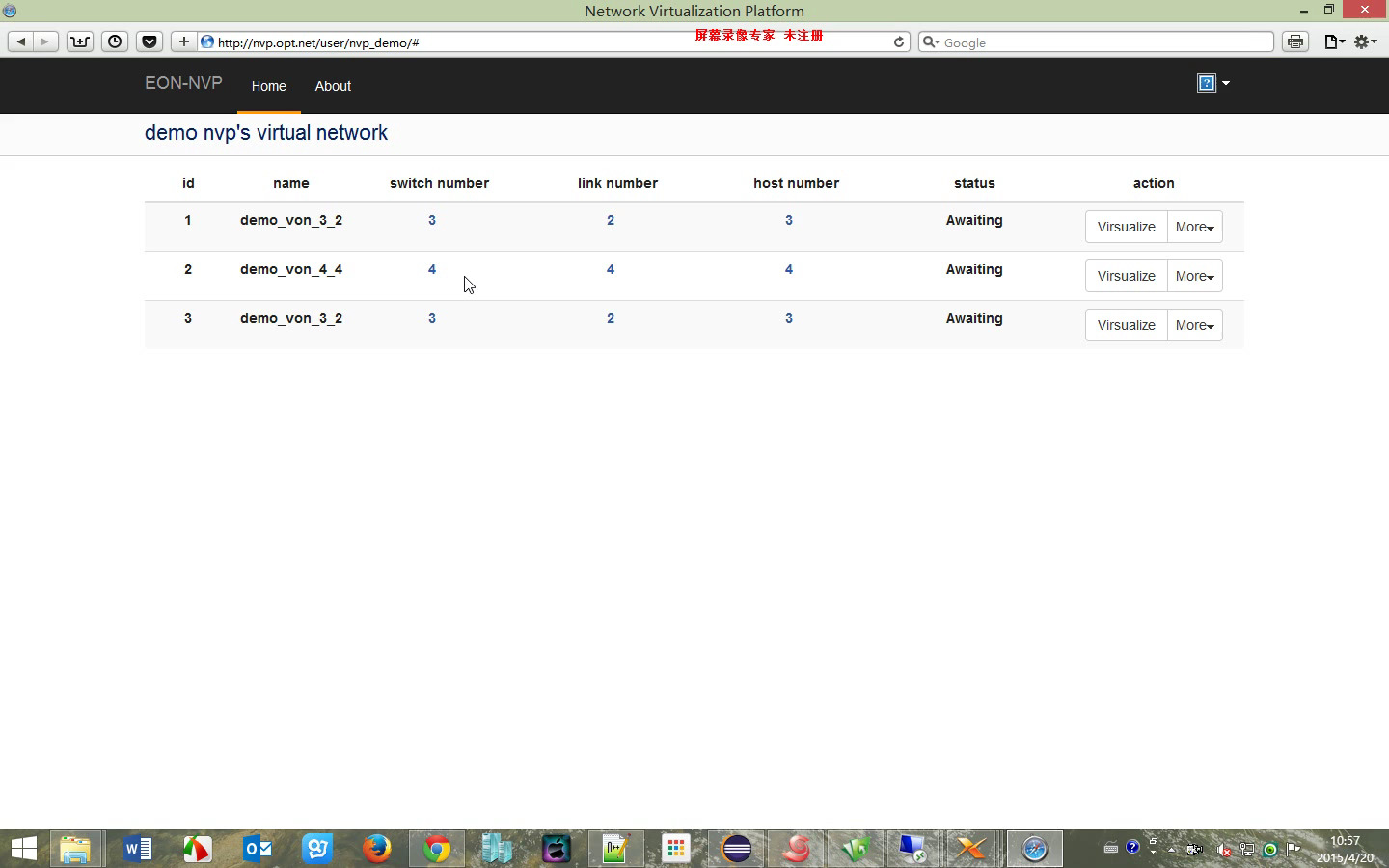
Model details your can refer to my defense ppt and the system part of my master thesis.
Known Issues
-
Robustness: current version is known to be not very robust
-
Speed: the response time (especially for starting a virtual network) is quite long, as the current VNE module is implemented in MATLAB
Applications
On-Demand and Reliable vSD-EON Provisioning with Correlated Data and Control Plane Embedding
Running time measurement is very important when you want to know the empirical time complexity of your “algorithm” or when you want to provide some progress status of your running program (for example, how long will
your program continue before finish a specific task). In MATLAB, you can use tik tok; in Python, you can use timeit or time package; What about in C++. In this post, we will give a few macros for you to conduct the time
measurement task.
Run Time Measurement Macros for C++
#include <chrono>
#define TIMING
#ifdef TIMING
#define INIT_TIMER auto start = std::chrono::high_resolution_clock::now();
#define START_TIMER start = std::chrono::high_resolution_clock::now();
#define STOP_TIMER(name) std::cout << "RUNTIME of " << name << ": " << \
std::chrono::duration_cast<std::chrono::milliseconds>( \
std::chrono::high_resolution_clock::now()-start \
).count() << " ms " << std::endl;
#else
#define INIT_TIMER
#define START_TIMER
#define STOP_TIMER(name)
#endif
Please make sure that your compiler support C++11, and you do use C++11 or higher to compile your code. For example, if you want to compile your C++ code with C++11 by using g++, you can simply add the following flag: -std=c++11
An Example
The following presents a simple example, which uses the above macros to measure running time (it assumes that the above macros are defined in tm.h).
#include <iostream>
#include "tm.h"
inline int add(int a, int b) {
return a + b;
}
int main()
{
// initialize a timer
INIT_TIMER
int repeat_times = 10000000;
// start the time
START_TIMER
for (int i = 0;i < repeat_times;++ i) {
add(100, 10);
}
// stop the timer and printing out the time information
STOP_TIMER("adding two integers for repeating " + std::to_string(repeat_times) + " times")
return 0;
}
If you run the above code correctly, you should see an output similar like below:
$ RUNTIME of adding two integers for repeating 10000000 times: 19 ms
Git is becoming one of the most popular version control tools. In this post, we introduce some commonly used commands for playing with Git.
Fast Commit
$ git commit -a -m "commit message"
Remember Credential on Windows
- configure for storing your credential
$ git config credential.helper store
$ git push http://example.com/repo.git
Username: <type your username>
Password: <type your password>
several days later
$ git push http://example.com/repo.git
[your credentials are used automatically]
Reset Last Commit
$ git commit -m "Something terribly misguided" # your last commit
$ git reset --soft HEAD^ # reset
It is extremely useful, when you encounter LARGE file problems
Skip Changes in Certain Files
$ git update-index --no-skip-worktree <file>
$ git add -p <file>
$ git update-index --skip-worktree <file>
Ignore Certain Files
If you want skip (ignore) certain type of files, the following configuration can be applied: Edit file “.gitignore”, and add the types you want to ignore, for example,
# ignore thumbnails created by windows
Thumbs.db
# Ignore files build by Visual Studio
*.user
*.aps
*.pch
*.vspscc
*_i.c
*_p.c
*.ncb
*.suo
*.bak
*.cache
*.ilk
*.log
[Bb]in
[Dd]ebug*/
*.sbr
obj/
[Rr]elease*/
_ReSharper*/
Push Local Branch to New Remote Repository
Suppose you have made a empty repository and named it myapp.git, you can:
$ git remote add <branch_name> <repository_url>
where <branch_name> can be any valid name you want. Then, you can push your local branch to the newly created remote repository by using
$ git push <branch_name> master
Resolve Large File Failure Problem
Suppose you git push your local repository to Github, however it failed because of some large-size files. And you might continue to experience git push failure, even if you have removed or ignore such large files. You can use the following commands to resolve such a problem by deleting those files in your history.
$ git filter-branch --index-filter 'git rm -r --cached --ignore-unmatch <file/dir>' HEAD
Of course, by using the above solution, you cannot upload your large file to Github. Recently, Github had released a tool to help you handle with large file. More details, you can refer to An open source Git extension for versioning large files